Computer Architecture
Why do you want to study Computer Architecture ?
Because the design, analysis, implementation concepts are vital to all aspects of computer science and engineering.
Because the course will equip you with an intellectual toolbox for dealing with a host of systems design challenges.
Course Goals
Understand
Interfaces (ex. Abstract Data Type = State + Operations)
Instruction Set Architecture ("The Hardware/Software Interface")
Engineering methodology/Correctness criteria/Evaluation method/Technology trend
The design techniques
Pipeline
Cache
Multiprocessor
Cache Coherence
Synchronization
Interconnection Network
인터페이스를 이해하기 위해서는 ADT의 operation과 state를 이해해야 한다.
함수를 이해하기 위해서는 함수의 input과 output의 패턴을 이해하면 된다.
Engineering methodology
Rule 1 : Identify and Optimize the Common Case
주로 일어나는 경우가 무엇인지 관찰한 후, 해당 경우의 Speed를 높여야한다.
Cache Memory Architecture
Common Case
Temporal Locality - 자주 참조되는(common case) Block들을 우선순위로 운영
ex. For Loop
Spatial Locality - 내 주위의 common case가 많으므로 Block단위로 운영
ex. Array
Rule 2 : Make the Rare Case correct and reasonably fast
Speed는 신경쓰지말고, 모든 Case(rare포함)에 대해 correct하게 처리해야한다.
Correctness criteria
Pipelined execution
Cache memory
DRAM Technology Trends
CPU는 트랜지스터를 속도를 높이는데 사용,
DRAM은 트랜지스터를 용량을 늘리는데 사용,
CPU와 DRAM간 속도차이가 발생, 이러한 차이를 줄이기 위해 Cache memory 등장.
Processor Clock Rate/Power Trends
냉각 한계점 - Clock과 Voltage는 비례하는데 높은 Voltage의 열을 Cooling시킬 수 없는 한계점, 따라서 더이상 Clock Rate를 높이지 못한다. 이러한 한계에 대처하기 위해 멀티코어 등장.
Virtualization
Process abstraction
time interrupt를 사용하므로써 하나의 CPU를 n개의 CPU로 동작 가능하게 한다.
Virtual Memory for each process
Locality를 이용하여 속도는 DRAM, 가격용량은 HD와 같은 illusion.
그대신, MMU와 exception mechanism(page fault)이 있어야 한다.
Cache Memory (100% H/W로 운영)
Locality를 이용하여 속도는 SRAM, 가격용량은 DRAM와 같은 illusion.
그대신, TLB가 있어야 한다.
Virtual Machine
1개의 Computer system을 n개가 있는 것처럼 illusion. 이렇게 확장하기 위해서
Computer system의 state를 잘 알아야 한다.
Virtual Machine Monitor(VMM)를 통해 서로 다른 OS를 멀티 플렉싱 시켜준다.
Decomposition of CPU (Execution) Time
CPU time = Seconds / Program
= (Instructions / Program)-(CISC유리) x
(Cycles / Instruction)-(RISC유리) x
(Seconds / Cycle)
RISC(Reduced Instruction Set Computer) vs. CISC(Complex Instruction Set Computer)
컴퓨터 시스템 초기, 메모리는 CPU의 속도를 따라가지 못해서 CPU는 메모리에서 한 번 받으면 오랫동안 Execute control를 가지고 있는게 이득이 되므로 명령어가 긴 CISC가 유리했다. 하지만, Cache와 Pipeline이 등장하게 되면서 메모리 속도가 CPU속도를 거의 따라가게 되면서 Pipeline에 유리한 RISC가 유리해졌다. 다시 말해, RISC의 경우, single chip microprocessor를 구성할 수 있는 충분한 트랜지스터가 확보된 후, 그 안에 cache memory를 넣을 수 있게 되었다.
Installed base 때문에 인텔은 패널티를 감수하면서 CISC를 유지하고 있으나, 내부적으로 결국 RISC 형태로 변환되어 실행된다.
RISC가 CPI비율면에서는 5배 좋고, Instruction executed ratio에서는 2배 나쁘므로, 총합적으로 봤을 때, Performance ratio에서는 RISC가 CISC보다 3배 좋다.
RISC
- Pipelined execution
- Cache memory
- Load/store architecture - 임의의 instruction에서 memory를 access하면 Pipeline이 복잡해지므로 memory에 접근할 때는 Load/Store instruction만 사용할 수 있도록 했다.
- transistor를 single chip에 많이 넣을 수 있게 되면서, Large/multi-level caches, co-processors, superscalar 등등 여러가지 능력치(?)를 얻을 수 있게 되었다.
CISC
- CISC는 instruction이 regular하지 않기 때문에 하드웨어 구현이 매우 복잡하다. 따라서 pipeline구현이 어렵다.
- high level language를 잘 분석해서 복잡한 instruction에 mapping해줘야 하기 때문에 컴파일러가 매우 복잡하다.
- 메모리의 속도가 느리다는 가정하에 (옛날 컴퓨터 모델) 한번의 instruction 수행에 많은 작업을 할 수 있으면 CISC가 유리하다. 다시 말해, CISC는 addressing mode가 복잡해서(여러 개의 partition으로 나뉘어짐) 여러개의 작업을 수행할 수 있다. 반면, RISC의 addressing mode는 간단하다.
MIPS Instruction Set (RISC) Architecture
- 32개의 general purpose registers
- Alignment restriction ; 하드웨어 구현을 효율적으로 하기 위한 제약
Word addresses must be multiples of 4 ( Load/store시 주소는 항상 4의 배수 )
- 간단한 addressing mode
* 서로 다른 프로그램들은 CPU Execution(control)을 가졌을 때, 각자 자기만의 register set을 가지고 있다는 illusion을 가진다. Context switching을 할 때, OS가 기존 register set내용은 stack에 저장하고, 나중에 다시 사용할 때 restore하기 때문에
Inter-operability
- register 번호마다 해야 할 일이 정해져 있다.
- convention , 일종의 규칙이다. 컴파일러들끼리 rule을 지키기 위해, Separate-compilation이 허용되므로, 예를 들어 이 파일은 이 컴파일러에게, 저 파일은 저 컴파일러에게 맡길 수 있다. 어차피 마지막은 object파일이 되므로 상관없다.
* arguments에 할당된 register개수는 4개이지만, argument가 5개 이상이면 Stack에 저장한다. 4개로 할당된 이유는 Common case가 거의 대부분 4개로 충분하기 때문, 그렇다고 5개 이상될 때 실행이 불가능한 것은 아니다. Stack을 사용함으로써 rare case도 보장해준다.
Compiling and Starting a Program
C Program
Compiler
Assembly language program
Assembler
Object 1: Machine language module & Object 2: Library routine (machine language) Linker
Executable: Machine language program (ex. a.out or a.exe)
Loader
Memory
* Linker : 서로 다른 compiler와 assembler에 의해 만들어진 object 코드를 모두 모아서 하나의 executable 파일을 만들어 준다.
변수
Local 변수 : 어느 한 function 내에서만 보여지면
Global 변수 : 어디서나 보여지면 (모두 static변수이다)
Static 변수 : 프로그램이 시작될 때 할당, 프로그램이 끝날 때 해제, 시작할 때 딱 한번 변수 초기화 진행
Automatic 변수 : Stack에 저장, 함수가 Call될 때 할당 , 정해진 규칙(stack)에 의해 할당과 해제되므로 semi-dynamic이라고 부른다.
Dynamic 변수 : malloc으로 할당할 때, 내 마음대로 할당과 해제를 하므로 dynamic이다.
Object File Example
linking하기 전 static변수가 있다는 표시 0을 지정한다. 메모리에 어디에 들어갈 지 모르기 때문에 일딴 0으로 표시한다. 어차피 나중에 Linker에 의해 번호표가 정해지게 되어있다. 다시 말해, Linking이 되기 전까지 static 변수는 메모리의 어디에 들어갈지 모른다.
MIPS Memory Allocation
서로 다른 object 파일들이 각각 static변수들을 가지고 있는데, 메모리에 올라가는 static data영역은 한 곳밖에 없으므로 여러개의 object 파일들의 static 변수들이 static data영역의 어느 위치를 차지할지 모른다. 따라서, Linker를 통해 하나로 묶어 정리한 후 static data영역에 차곡차곡 정리해서 넣는다.
Basics of Datapath
Combinational Logic Elements (AND,OR,NOT, Adder,ALU, Multiplexer)
state가 없다. 즉, 기억능력이 없다.
output은 input에 의해 100% 결정된다. behavior을 input/output table로 그릴 수있다.
Storage Elements
내부적인 어떤 상태를 저장하기 위해 Clock이 존재한다. 즉, state가 있다. 기억능력o
Clock의 falling edge가 되면 state가 순간 바뀐다.
* register 값을 바꾸려 할 때 setting
1. 바꿀 register 번호 (write register)
2. 쓸 data값 (write data)
3. control signal on (RegWrite on)
4. clock (falling edge)
Storage Elements
Register File : 읽고 쓰기가 동시에 가능, 따라서 복잡한 logic을 가지고 있다. 비쌈
Memory : 읽기, 쓰기 중 한개씩만 수행 가능하다. 비교적 간단한 logic. 쌈
Clocking
- Input값을 일정시간동안 유지하고 있어야 한다. (Set-up time, Hold time)
- clock의 falling edge가 발생하고 어느 정도시간이 지나야지만 바뀐 state가 output로 나오기 때문
- Clock이 모든 storage element에게 가는데, 실제로 똑같은 시점에 도달하지 못한다. 각각의 전기선의 길이가 다를 수도 있고, 예측할 수 없는 noise때문이다. 따라서 이를 보상하기 위해 skew time이 필요하다. 가장 빨리 도착한 놈과 가장 늦게 도착한 놈의 시간차이를 skew time이라고 한다.
- Cycle time은 어떤 storage element의 output이 combinational logic을 거쳐 어떤 storage element의 input으로 들어가기까지의 시간을 말한다.
Single-Cycle Implementation
- 모든 Instruction실행이 한 cycle안에 끝나게 된다. 대신, cycle time은 굉장히 길다.
- Control bit의 값(RegWrite,MemWrite..)들은 명령어에 의해 자동적으로 generate된다.
- Single-Cycle이기 때문에 clock의 falling edge가 되기 전까지 명령어 fetch, decode, 연산 수행, 메모리 access 등 명령어의 모든 일을 수행한다. 그런 다음 falling edge가 되면 pc+4의 명령어가 실행되면서 다음 명령어가 실행된다.
- 하지만, 값들은 falling edge가 일어나기 전에는 바뀌지 않는다. falling edge가 일어나기 전까지 register 또는 memory에 적힐 값들이 기다리고 있다가, falling edge가 일어나면 모든 값들이 바뀐다. 물론 pc값도.
Single-Cycle 단점
- 명령어들 특징마다 소요되는 시간이 다르다. 예를 들어, Arithmetic은 짧은 시간에 끝나고, Load/Store은 비교적 긴 시간을 요구한다. 그리고 프로그램당 사용하는 명령어의 빈도수가 다르다. 예를 들어, Arithmetic은 한 프로그램당 48%를 차지하고, Store는 11%밖에 차지하지 않는다. 이런 점을 비춰보았을 때, Single-cycle은 가장 오랜 시간을 요구하는 명령어(Load)에 맞춰야 하는데, 이는 매우 비효율적인 행동이다.
- 한 Cycle에 모든 일이 일어나야되기 때문에 중복된 기능을 하더라도 모두 독립적인 유닛을 가져야 한다. 예를 들어, ALU와 Memory의 유닛은 2개나 필요하다. 이는 자원을 비효율적으로 사용하는 행동이므로 개선이 필요하다.
* Multiplexer : 여기서도 올 수 있고, 저기서도 올 수 있으면, 즉 들어오는 방향이 한개 이상일 경우 사용한다. Multiplexer와 Control sig을 이용해 한 방향만 선택할 수 있다.
** Instruction 구현 방식
Sequential Implementation : 한 명령어가 끝나고 다음 명령어 실행
Single Cycle Implementation : 하나의 instruction을 하나의 cycle에서 실행
Multi Cycle Implementation : 하나의 instruction을 여러 cycle에 걸쳐 실행
Overlapped Implementation : 명령어들이 서로 overlap되면서 실행된다.
Pipeline
Multi-cycle Implementation
- Single-Cycle에서의 하나의 Clock cycle time을 여러 단계로 나눠 clock cycle time을 줄인다.
- 가장 긴 Load 명령어에 cycle time을 맞출 필요없이 상대적으로 CPU가 명령어를 수행하는 단계 중 가장 긴 단계(fetch, decode, ALU operation, write .. )에 cycle time을 맞춘다. (Cycle time 최적화)
- Load/Store는 5step, ALU는 4step, Jump와 branch는 3step만 진행하면 된다.
- 각 cycle마다 하드웨어(ALU)를 다양한 용도로 사용된다. 따라서 ALU와 Memory는 하나씩만 있어도 괜찮다. (리소스 최적화)
- 여러 단계로 나눠진 구조를 자연스럽게 이어주기 위해서 단계 중간중간마다 temporary register가 존재한다. 가장 먼저 도착한 놈과 늦게 도착한 놈의 시간차이가 존재하므로 먼저 온 놈은 잠시 저장했다가 늦게온 놈의 페이스에 맞춘다.
- Multi-cycle의 Step : 1. Instruction fetch - 2. Instruction decode/register fetch - 3. Execution, address computation, branch/jump completion - 4. Memory access or R-type completion - 5. Memory read completion
** Speculative execution
- 첫 번째 STEP : jump, branch는 pc+4가 아니지만, 공통적으로 기본적으로 일단 pc+4 연산을 해준다.
- 두 번째 STEP-1 : Load같은 명령어의 경우 fetch 단계에서 2개의 register가 구지 필요없지만 speculative execution을 구현하기 위해 일단 2개 다 읽는다.
- 두 번째 STEP-2 : 내가 지금 branch가 아닐 수 있는데 branch target 주소를 계산한다.
- Philosophy : 자원이 노는 것보다 나중에 instruction(branch)이 일어 날 것을 대비해서 미리 값을 계산해 놓는게 낫다 비록 사용안할지라도, 무엇보다 어차피 읽는 동작은 피해를 끼칠 염려가 없다.
** Finite State Machine
Single-cycle에서의 control signal은 32bit 명령어만 보면 다 알수 있다. 하지만, Multi-cycle에서는 각 step마다 control signal이 모두 다르다. 내가 어느 state에 있는지에 따라 finite state machine controller를 사용해 모든 control signal을 만들 수 있다.
** Exception vs. Interrupts
공통점 : 발생하면 Operating system으로 control이 넘어간다.
차이점 : 지금 실행되고 있는 내부 상황에서의 예외 사항 (Exception), 외부에서 비동기적으로 발생하는 예외사항 (Interrupt)
현재 실행되고 있는 Instruction은 인터럽트 서비스 루틴이 실행됬는지 전혀 몰라야 된다.
Pipelining (Overlapped Execution)
즉, 한 Cycle을 Sub cycle 2개로 쪼개서 WB 먼저 빨리 write하고 그 다음 ID에서 2개 read한다.
⑵ Data Hazard ( RAW(read after write) hazard )
- 매 Cycle마다 (매 Step마다) 새로운 명령어가 들어간다. 새로운 명령어와 기존의 명령어가 서로 Overlap된다.
- 즉, 전체적으로 보았을 때 매 Cycle마다 하나의 명령어가 끝난다. ( Steady State )
- Pipelining의 Step : 1. Instruction fetch step (IF) - 2. Instruction decode/register fetch step (ID) - 3. Execution/effective address step (EX) - 4. Memory access (MEM) - 5. Register write-back step (WB)
Major Hurdles of Pipelining
⑴ Structure Hazard ( Resource Duplication )
① Multi-port register - MEM과 IF가 같은 라인에 있는 경우
⑴ Structure Hazard ( Resource Duplication )
① Multi-port register - MEM과 IF가 같은 라인에 있는 경우
하나의 메모리에 2곳에서 접근해오면 자원 충돌 우려
명령어 메모리(I-Cache)와 데이터 메모리(D-Cache)를 따로 만들어서 해결
② Time-multiplexed - WB과 ID가 같은 라인에 있는 경우
하나의 레지스터에 2곳에서 접근해오면 자원 충돌 우려
레지스터 파일을 구현할 때 gate를 많이 써서 한 cycle에 2개의 read, 1개의 write가 가능하도록 만들어서 해결하나의 레지스터에 2곳에서 접근해오면 자원 충돌 우려
즉, 한 Cycle을 Sub cycle 2개로 쪼개서 WB 먼저 빨리 write하고 그 다음 ID에서 2개 read한다.
⑵ Data Hazard ( RAW(read after write) hazard )
ADD 연산을 하기 이전에 Register 값을 읽게 되는데, 이는 Correctness에 위배된다.
① (Internal) Forwarding
ALU를 통해 값이 만들어지자마자 필요한 놈한테 곧바로 보낸다.
Delay가 없이 실행가능하다.
예를 들어, ALU output을 다음 cycle의 ALU input으로 곧바로 넣어준다.
그래도 Load는 1 cycle 뒷다리(stall)를 잡아줘야한다. (그래도 최소화)
①-ⓐ Forwarding Logic

①-ⓑ Forwarding Example


여기까지는 문제없다.

직전 명령어의 Rt값($2)과 현재 명령어의 Rs($2)값이 동일하기 때문에, Correctness를 지키기 위해서 Forwarding 해준다. 4번째 pipeline에서 ALU출력이 Forwarding Unit의 control signal에 의해 곧바로 ALU입력으로 들어가는 것을 확인할 수 있다.(Forwarding)


다시 말해서, Forwarding만으로는 LOAD를 해결하지 못하므로 Stall or NOP or Bubble을 추가한다. (어쩔수 없이 한개의 명령어 time 희생)


다시 말해, ⓐ전 명령어가 LOAD이고 (MEM control signal을 통해 확인), ⓑLOAD의 Rt와 현재 명렁어의 Rs가 같으면 forwarding만으로는 부족한 것을 알고, bubble(NOP, stall)을 끼워넣어준다.
② Freezing the pipeline (뒷다리를 잡는 방법)
보통 2 cycle 뒷다리를 잡으면, sequential하게 구현될 수 있다.
만약, 어떤 경우라도 4 cycle 뒷다리를 잡으면 Sequential execution 한다.하지만, 게속 4 cycle씩이나 뒷다리를 잡으면 pipeline의 성능향상은 없다.
②-ⓐ Stall Logic
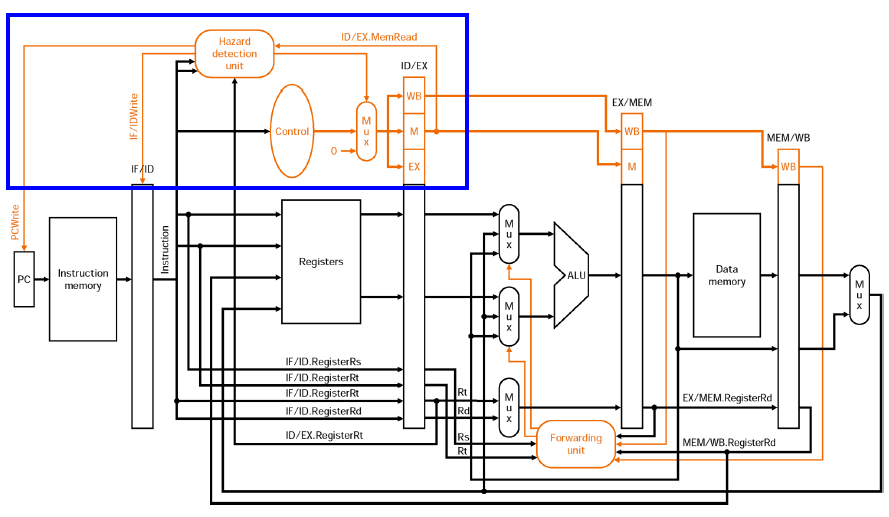
ⓐ 직전 명령어가 LOAD인지 확인(ID/EX MemRead가 1인지 check)
ⓑ 직전 명령어의 LOAD의 Rt와 현재 명령어의 Rs 2개 중 한개가 같을 경우에
stall 여부를 결정하게 된다.
- ⒝ stall 여부를 결정하게 되면,
ⓐ Hazard detection unit은 Control와 연결된 Mux를 조절하여 모든 Control signal을 0으로 만들어 주고(Memwrite와 Regwrite를 못한다면 Machine state를 바꿀 수 없으므로 nop와 똑같다),
ⓑ PCWrite와 IF/IDWrite를 hold시켜줌으로써 다음 clock에도 똑같은 명령어 작업을 하도록 해줌으로써(뒷다리를 잡음),
현재 명령어를 NOP으로 만들어주는 듯한 효과를 준다.
②-ⓑ Stall Example

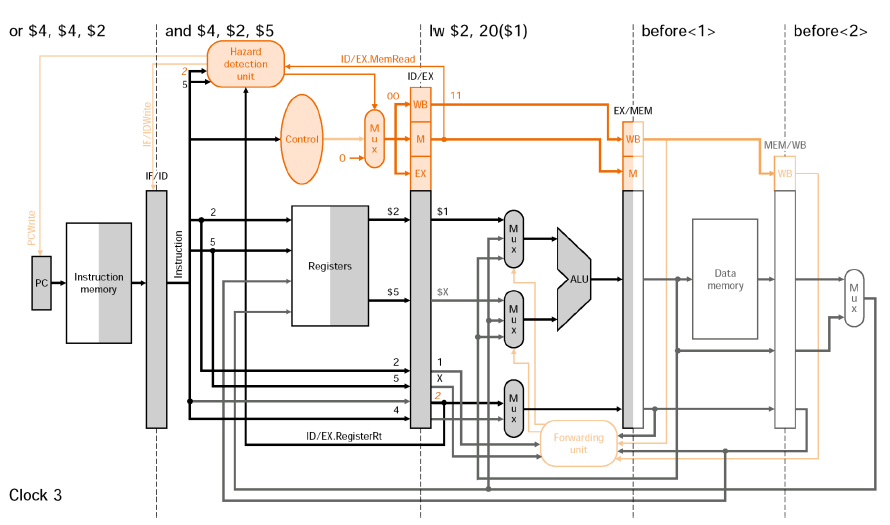


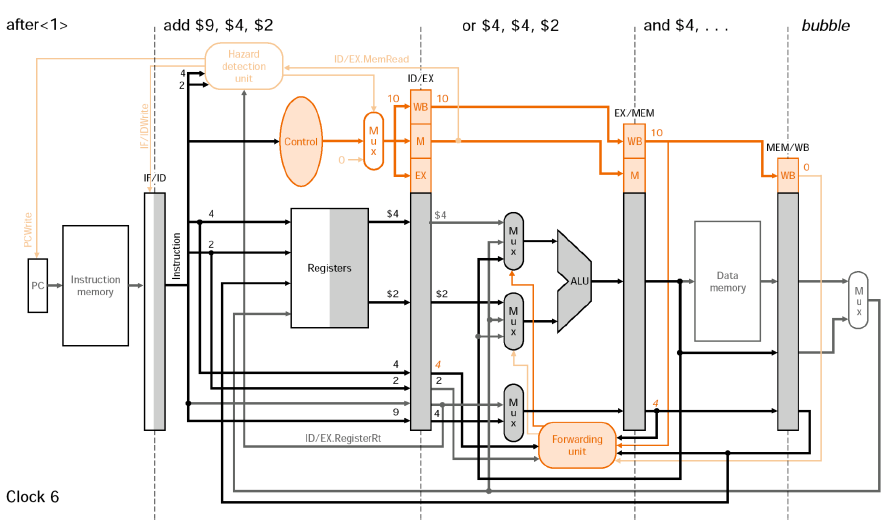

③ Compiler scheduling
⑶ Control Hazard
caused by PC-changing instructions (Branch, Jump, Call/Return)
일반적으로, pc가 sequential하게 pc+4가 되는 명령어가 아니고, non-sequential하게
pc값이 바뀌는 명령어(branch,jump) 때문에 발생하는 문제
- 예를 들어, branch 명령어(if문)가 완전히 끝나야지 다음 명령(pc+4)을 쓸지,
branch target 명령을 쓸지 알수 있기 때문에...
- jump할 주소를 알아야 다음 명령(pc+4)를 수행할 수 있다.
① Optimized branch processing (초전박살: 최대한 branch명령어를 빨리 끝낸다)
branch는 패널티가 크기 때문에 최단 cycle에 실행되도록 한다.
1. Find out branch taken or not early
- simplified branch condition ( branch 조건을 간략화 )
2. Compute branch target address early
- extra hardware (원래 ALU를 쓰지 않고, 앞에서 special adder를 사용)
*최종목표 : Branch명령을 2 cycle로 끝내기 (1 cycle 패널티만 발생)
①-ⓐ Control(Branch) Hazard Logic - 핵심 : branch 2 cycle(clock)만에 초전박살!!!

Branch가 실행되는 2번째 clock에서 equal unit을 통해 branch 조건을 확인해보고 조건이 만족안될 경우 그냥 무시하고 지나가면 되고, 조건이 만족될 경우 친구따라 강남 온 친구를 취소해야한다. 즉, Control Signal의 IF Flush=1해서 IF/ID를 모두 0으로 만들어버린다. 그러면 명령어 32bit 모두 0이 되어 add$0,$0,$0이라는 NOP명령어가 된다.
①-ⓑ Control(Branch) Hazard Example


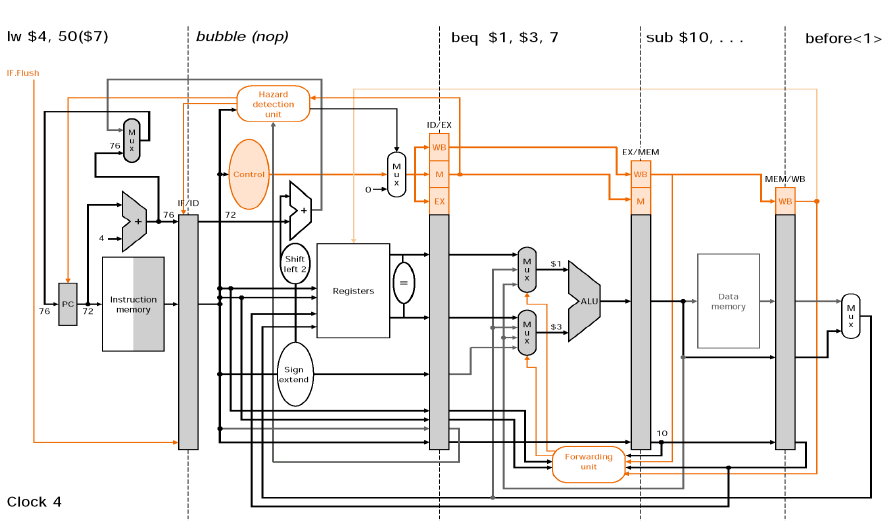
그 결과 bubble(nop)을 만들어주고, target주소인 lw명령어를 실행하게 된다.
결과적으로 Branch명령어는 초전박살로 2 cycle(clock) 이내에 실행하게 되었다. 하나의 nop가 생기는 penalty는 감수한다.
Branch Prediction
모든 Branch에 대해서 untaken이라고 생각해서 무조건 pc+4를 해준다.
1. 실제로 untaken이면..
어라? 진짜 아니네? 그냥 아무일 없는 것처럼 게속 실행한다.
2. taken이면..
바로 다음 라인의 파이프 라인을 모두 idle하게 만든다. (nop 명령어)
즉, MEM, WB 단게에서 메모리 업데이트를 못하게 한다.
Delayed Branch (영혼을 팔아먹음)
바로 뒤에 있는 명령어(Delay slot)는 branch 조건여부에 상관없이 무조건 실행된다.
즉, if문 내부코드가 branch여부와 상관없이 실행된다. Delay slot으로..
taken되면 문제없고, untaken이 되면 Delay slot을 nop으로 만든다.
** Speculative Execution : branch를 만나면 다음 cycle은 prediction된 명령으로
실행한다. 그리고 prediction한게 맞을 때까지 Machine State를 update하면된다.
Pipelined Datapath and Control
Pipelined Datapath

- Temporary register를 일반화하여 일종의 큰 register라고 생각한다.
- 앞 단계로 나아가면서 내가 이후에 필요할 것 같은 내용을 모두 저장한다.
- 한 번 지나가면 끝이므로 심지어 명령어 32bit와 target register 주소까지 끼고 가야된다.
Pipelined Datapath with Control Signals Connected

Exception Handling
Datapath with Controls to Handle Exceptions

- Except PC : Exception을 낸 PC를 포함 - 나중에 OS가 exception handling을 마치고 다시 원래대로 돌아올 수 있도록
Exception Handling Example

Sequential exception behavior을 지키기 위해서 모두 죽는다. OS exception 서비스 루틴을 하고 다시 exeption 걸린놈이 처음부터 시작해야하므로..

Advanced Pipelining
⑴ Superpipelining

stage 하나하나가 더 짧아졌기 때문에 clock을 훨씬 더 빨리 돌릴 수 있다.
single cycle implementation에서 multiple cycle implementation을 발전된 역사를 살펴보면 하나의 명령어를 여러개의 단계로 나눠서 실행하여 cycle time을 극대화하여 속도를 빠르게 했다는 점인데, (예를들어 5-step load와 달리 add는 3-step안으로 끝낼수 있다.) 이러한 특징들을 극대화 시키기 위해, 최대한 stage를 많이 나누고 clock freq를 높임으로써 성능을 높일 수 있도록 해준다.
⑵ Superscalar

한 cycle(clock)에 2개 이상의 명령어들을 실행할 수 있다. 하지만, 명령어 종류가 고정적이다.
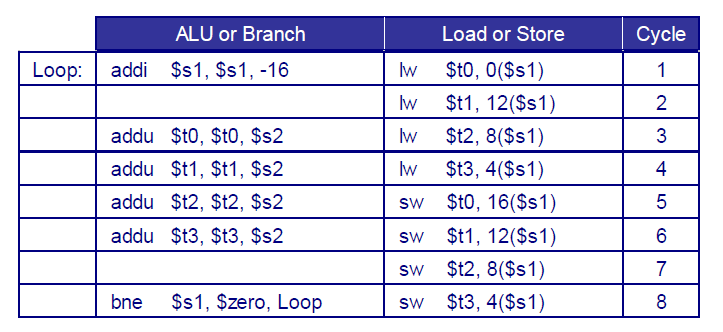
⑶ Dynamic Pipeline Scheduling
out-of-order execution 등장. 기다리는게 억울한 명령어가 concurrent하게 먼저 실행할 수 있도록 명령어들을 scheduling해주는 방법.
** Multi-core로 가면서 superscalar, out-of-execution 하는 것보다 간단한 방법(원래대로)으로 코드를 parallel하게 실행한다. 그 이유는 전력소모면에서 훨씬 효율적이기 때문이다. superscalar나 out-of-execution을 하면 단순히 pipelining하는 것보다 전력소모가 많다. 따라서 muti-core로 갈 때는 오히려 advanced 하지않고 원래 simple한 pipelining을 하여 에너지 소모를 줄인다. (모바일 CPU나 서버 컴퓨팅 환경에서는 전력소모가 이슈)
** 1. Sequential Execution 과 2. Exception Sequential Behavior 만 지켜주면 어떠한 방법을 써서 성능향상 시켜도 된다.
Memory Hierarchy
VLSI가 발전함에 따라 한 chip에 들어가는 트렌지스터를 DRAM은 메모리 용량을 키우기 위해 증가시키고, CPU는 오로지 속도 향상을 위해 증가시킨다면 둘 사이의 속도 gap은 더 커지게 되었다. 대안책으로 Cache memory가 등장하였다.
Temporal and Spatial Localities

- COLUMN - Spatial locality - ARRAY
Open Source Software Learning Community (Korea)
Computer Architecture, 서울대학교, 민상렬 교수님
댓글
댓글 쓰기